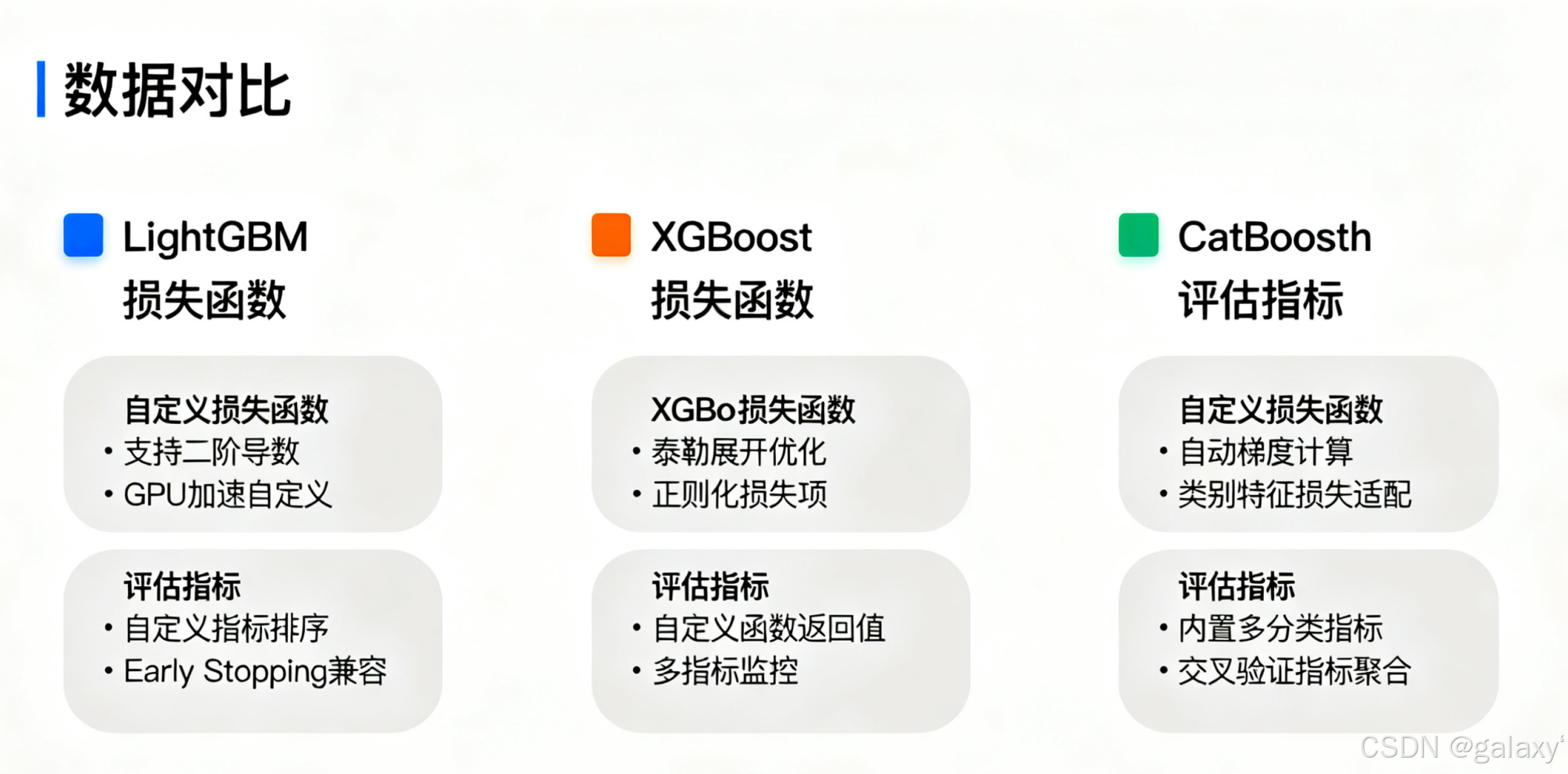
LightGBM、XGBoost和CatBoost自定义损失函数和评估指标
@TOC
函数(缩放误差)
传统的均方误差(MSE)和平均绝对误差(MAE)对所有预测值给予相同的权重,但在某些场景下,更关心相对误差而非绝对误差。缩放误差通过将误差除以真实值来实现这一目标:
1 | |
这样设计的优势:
- 对于大数值和小数值的预测给予相对平等的权重
- 避免大数值主导损失函数
- 更适合预测范围变化很大的场景
数学原理
损失函数定义
设损失函数为:
1 | |
其中:
y是真实值ŷ是预测值threshold是防止除零的最小阈值
梯度计算
对于梯度提升算法,我们需要计算损失函数对预测值的一阶导数(梯度)和二阶导数(Hessian):
设 d = max(y, threshold),e = (y - ŷ) / d
- 一阶导数(梯度):
∂L/∂ŷ = -2e/d - 二阶导数(Hessian):
∂²L/∂ŷ² = 2/d²
评估指标
配套的评估指标使用缩放平均绝对误差(Scaled MAE):
1 | |
LightGBM实现
自定义损失函数
1 | |
自定义评估指标
1 | |
使用方式
1 | |
XGBoost实现
自定义损失函数
1 | |
自定义评估指标
1 | |
使用方式
1 | |
CatBoost实现
CatBoost的自定义函数需要用类的形式实现。
自定义损失函数
1 | |
自定义评估指标
1 | |
使用方式
1 | |
框架对比
| 特性 | LightGBM | XGBoost | CatBoost |
|---|---|---|---|
| 损失函数形式 | 函数 | 函数 | 类方法 |
| 参数名称 | objective |
obj |
objective |
| 数据获取 | train_data.get_label() |
dtrain.get_label() |
直接传入 targets |
| 评估指标形式 | 函数 | 函数 | 类方法 |
| 评估返回格式 | (name, value, is_higher_better) |
(name, value) |
error_sum, weight_sum |
| 权重支持 | 自动处理 | 自动处理 | 需手动处理 |
| 实现复杂度 | 简单 | 简单 | 中等 |
实际应用
适用场景
- 新能源功率预测:风电、光伏功率预测范围从0到满功率
- 金融风险评估:不同规模公司的风险评估
- 销售预测:不同产品类别的销售额预测
- 网络流量预测:不同时段流量变化很大
常见问题
1. 为什么要设置最小阈值?
问题:直接用真实值作为分母会遇到什么问题?
答案:
- 当真实值为0或接近0时,会导致除零错误或梯度爆炸
- 设置最小阈值可以保证数值稳定性
- 阈值的选择应根据数据的实际分布来确定
2. 梯度和Hessian计算错误怎么办?
问题:如何验证梯度计算的正确性?
答案:可以用数值微分验证:
1 | |
3. 不同框架的性能差异
问题:三个框架在使用自定义损失函数时的性能如何?
答案:
- LightGBM:通常最快,内存效率高
- XGBoost:稳定性好,文档完善
- CatBoost:对类别特征处理好,但自定义函数实现相对复杂
4. 超参数调优建议
1 | |
LightGBM、XGBoost和CatBoost自定义损失函数和评估指标
https://qzkq.github.io/2026/01/01/LightGBM、XGBoost和CatBoost自定义损失函数和评估指标/