Pytorch详解-模型保存与加载、Finetune 模型微调、GPU使用、nvidia-smi详解、TorchEnsemble 模型集成库、torchmetrics 模型评估指标库
@[TOC](Pytorch详解-模型保存与加载、Finetune 模型微调、GPU使用、nvidia-smi详解、TorchEnsemble 模型集成库、torchmetrics 模型评估指标库)
1 | |
保存与加载的概念(序列化与反序列化)
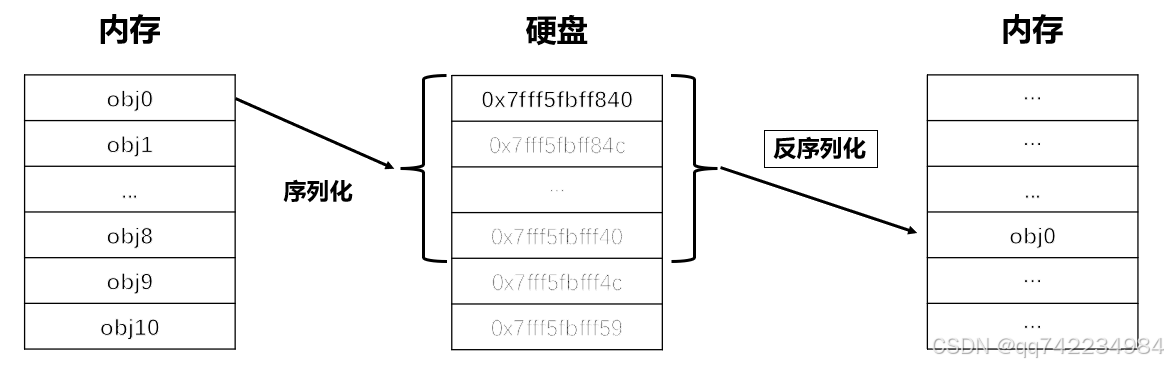
torch.save / torch.load
如果模型是在 GPU 上训练的,但在 CPU 上加载,需要使用 map_location 参数将模型转移到 CPU 上。反之亦然。
torch.save 用于将 PyTorch 对象保存到磁盘文件中。它可以保存各种类型的对象,包括模型、张量、字典等。
1 | |
1 | |
torch.load 用于从磁盘文件中加载之前保存的 PyTorch 对象。
1 | |
1 | |
两种保存方式
设备兼容性:如果模型是在 GPU 上训练的,但在 CPU 上加载,需要使用 map_location 参数将模型转移到 CPU 上。反之亦然。
在 PyTorch 中,有两种常见的模型保存方式:一种是保存整个模型,另一种是仅保存模型的权重。这两种方式各有优缺点,适用于不同的场景。下面分别介绍这两种保存方式及其使用示例。
- 保存整个模型
保存整个模型意味着不仅保存模型的权重,还保存模型的结构以及其他相关信息。这种方式非常适合于需要完整复制模型的情况,例如模型部署或分享给他人。 - 仅保存模型的权重
仅保存模型的权重意味着只保存模型的参数,而不保存模型的结构。这种方式更灵活,因为你可以在加载权重时重新定义模型结构。这种方式适合于模型训练后需要在不同环境中部署的情况。
Finetune 模型微调
模型微调(Fine-tuning)是一种常见的机器学习技术,特别是在深度学习领域中,它允许我们利用预训练模型的知识来解决新的相关任务。通过微调,我们可以调整预训练模型的部分或全部参数以适应新任务的数据集。
基本概念
- 预训练模型:在大规模数据集上预先训练好的模型。
- 微调:在预训练模型的基础上,使用较小的新数据集进行额外的训练,以适应特定的任务。
- 冻结层:在微调过程中不更新某些层的权重,通常保留预训练模型的基础特征提取部分。
- 解冻层:允许更新某些层的权重,以适应新任务的需求。
传统微调(Conventional Fine-tuning)
- 加载预训练模型:选择一个在大规模数据集上预训练好的模型。
- 修改模型结构:根据新任务的需求,可能需要修改模型的输出层。
- 冻结部分层:为了保持预训练模型的基础特征不变,可以冻结一些层。
- 训练模型:使用新数据集对模型进行训练。
- 解冻层并再次训练:为了更好地适应新任务,可以选择解冻更多层并进行额外的训练。
参数高效的微调(Parameter-Efficient Fine-tuning)
- Adapter Layers:在预训练模型的每一层之间插入小型的适配器层,这些层会被微调,而原始模型的参数保持不变。
- Prefix Tuning:在模型的输入端附加一个可训练的前缀,这些前缀会被微调,而模型的其他部分保持不变。
- LoRA (Low-Rank Adaptation):通过引入低秩矩阵来更新模型的权重,而不是直接更新所有权重。
GPU使用
CPU(central processing unit, 中央处理器)cpu主要包括两个部分,即控制器、运算器,除此之外还包括高速缓存等
GPU(Graphics Processing Unit, 图形处理器)是为处理类型统一并且相互无依赖的大规模数据运算,以及不需要被打断的纯净的计算环境为设计的处理器,因早期仅有图形图像任务中设计大规模统一无依赖的运算,因此该处理器称为图像处理器,俗称显卡。
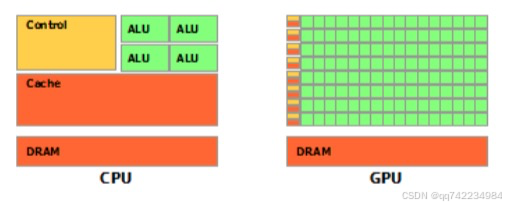
绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元,从示意图中看出,gpu的重点在计算,cpu的重点在控制,这就是两者之间的主要差异。
PyTorch的设备——torch.device
torch.device 的基本用法
1 | |
创建 torch.device 实例:
- 通过字符串创建:torch.device(“cuda”) 或 torch.device(“cpu”)
- 通过字符串和设备编号的形式创建:torch.device(“cuda:0”) 或 torch.device(“cuda:1”) (如果你有多个 GPU)’
检查设备:
- 使用 device.type 获取设备类型(例如 “cuda” 或 “cpu”)。
- 使用 device.index 获取设备索引(如果指定了设备编号)。
将张量和模型移动到特定设备:
- 使用 .to(device) 方法将张量或模型移动到指定的设备上。
- 使用 .cuda() 或 .cpu() 方法也可以移动张量或模型,但推荐使用 .to() 方法,因为它更通用且易于理解。
torch.cuda常用函数
1 | |
多gpu训练——nn.DataParallel
torch.nn.DataParallel 是 PyTorch 中的一个类,用于实现数据并行处理,使得模型可以在多个 GPU 上并行运行。
1 | |
module:
- 类型:torch.nn.Module
- 描述:要并行化的模型模块。
device_ids:
- 类型:list of int or None
- 默认值:None
- 描述:指定要在哪些 GPU 上并行化模型。如果为 None,则默认使用所有可用的 GPU。
output_device:
- 类型:int or None
- 默认值:None
- 描述:指定输出结果所在的设备。如果为 None,则默认为 device_ids[0]。
dim:
- 类型:int
- 默认值:0
- 描述:指定在哪个维度上拆分输入数据。通常情况下,使用默认值 0 即可,这意味着按批次拆分数据。
torchmetrics 模型评估指标库
TorchMetrics代码结构
torchmetrics 的代码结构设计得非常模块化和易于扩展,以支持各种类型的评估指标。
核心组件
Metric 类 (torchmetrics.Metric)
描述:这是所有指标类的基础类,提供了通用的功能,如状态管理、更新和计算逻辑。
关键方法:
- _init_: 初始化方法,定义了状态变量。
- update: 接收预测和目标数据,并更新内部状态。
- compute: 基于内部状态计算指标值。
Task-specific Metrics
描述:针对不同任务的指标,如分类、回归、推荐系统等。
示例:
1 | |
Composite Metrics
描述:可以组合多个指标,以便一次计算多个指标。
示例:
1 | |
TorchEnsemble 模型集成库
BaggingClassifier
描述:基于 Bagging(自助法)的分类集成模型。
用途:适用于分类任务,通过多次从训练集中有放回地抽样来构建多个基模型,然后将它们的预测结果进行投票或平均。
BaggingRegressor
描述:基于 Bagging 的回归集成模型。
用途:适用于回归任务,同样通过多次从训练集中有放回地抽样来构建多个基模型,然后将它们的预测结果进行平均。
GradientBoostingClassifier
描述:基于梯度提升的分类集成模型。
用途:适用于分类任务,通过逐步添加新的基模型来修正现有模型的错误,从而提高整体性能。
GradientBoostingRegressor
描述:基于梯度提升的回归集成模型。
用途:适用于回归任务,采用类似的方法逐步添加新的基模型来改进预测。
StackingClassifier
描述:基于 Stacking 的分类集成模型。
用途:适用于分类任务,通过使用多个基模型的输出作为特征来训练一个元模型,从而进行最终的预测。
StackingRegressor
描述:基于 Stacking 的回归集成模型。
用途:适用于回归任务,采用类似的方法使用多个基模型的输出作为特征来训练一个元模型。
nvidia-smi详解
nvidia-smi 是 NVIDIA 提供的一款命令行工具,用于监控和管理 NVIDIA GPU 的状态和性能。这个工具可以提供关于 GPU 的实时信息,包括但不限于温度、功耗、显存使用情况、驱动版本等,非常适用于诊断、优化和管理 GPU 资源。
基础用法
nvidia-smi 显示所有 GPU 的概览信息,包括 GPU 名称、GPU ID、PCI Bus ID、GPU 温度、风扇速度、显存使用情况、GPU 利用率等。
详细查询
1 | |
输出格式控制
1 | |
高级功能
1 | |
示例
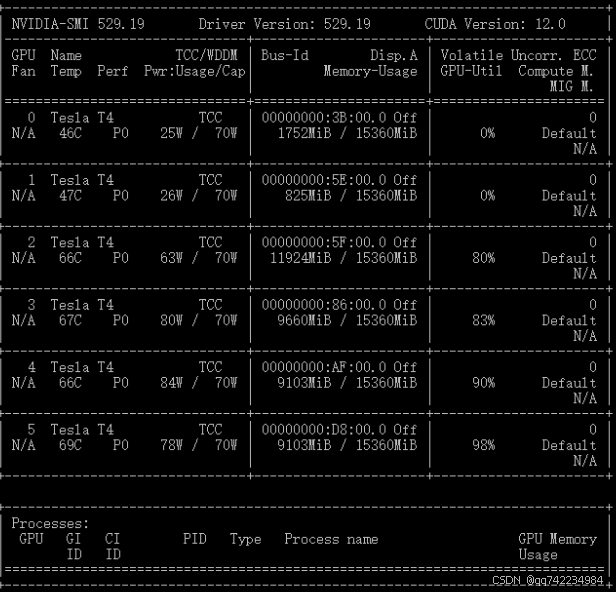
1 | |
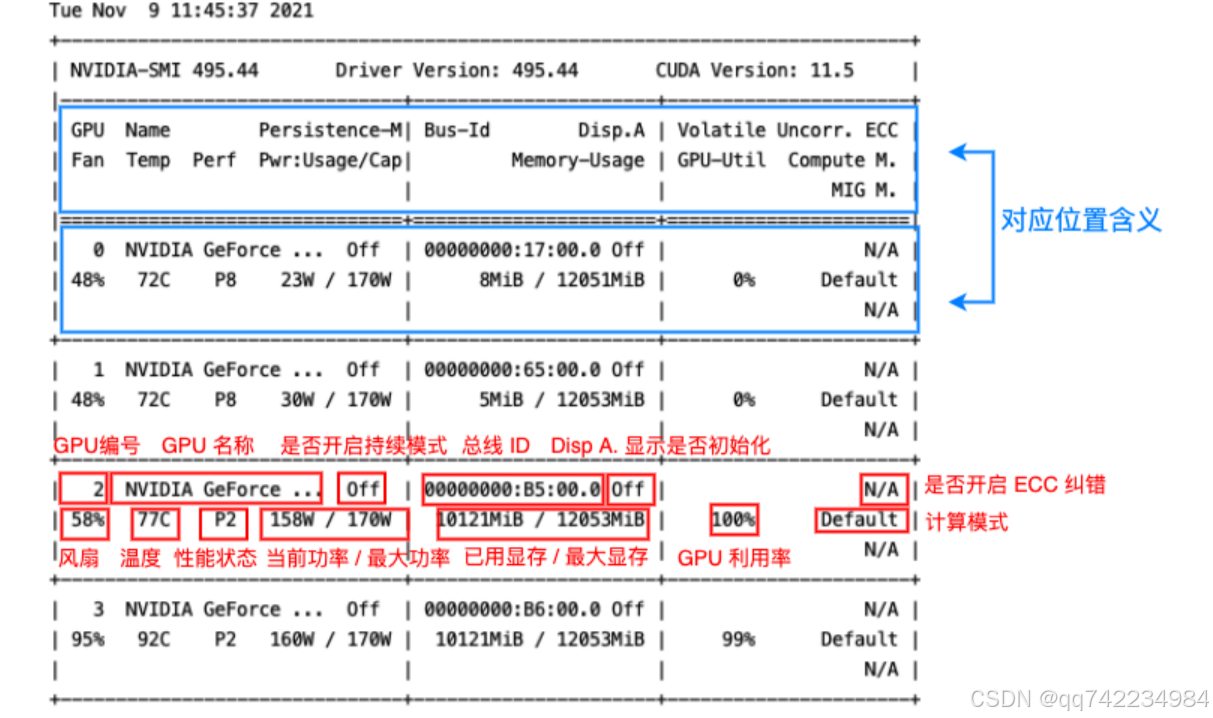
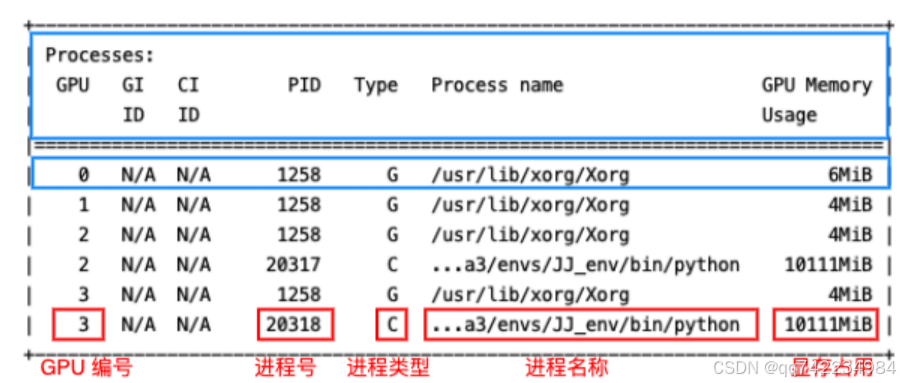
显存与GPU的区别
显存(Video Memory 或 VRAM)与 GPU(Graphics Processing Unit)是构成现代显卡的两个重要组成部分,它们各自承担着不同的角色,共同协作以提供图形处理能力。
GPU(图形处理器)
定义: GPU 是一种专门设计用于处理图形相关计算的微处理器。它拥有大量的并行处理单元,可以同时执行多个计算任务,非常适合处理图像渲染、视频解码、物理模拟、机器学习等高度并行化的任务。
作用: GPU 主要负责执行复杂的图形算法,如像素着色、顶点变换、纹理映射、光线追踪等,以生成高质量的视觉效果。此外,现代 GPU 还被广泛应用于通用计算领域(GPGPU),如科学计算、深度学习、加密货币挖矿等。
架构: GPU 架构通常包含多个流处理器(Streaming Multiprocessors,SMs)或计算单元(Compute Units,CUs),每个单元内包含多个 ALU(算术逻辑单元)和 FPUs(浮点单元),用于并行计算。
显存(VRAM)
定义: 显存是显卡上的专用存储器,用于存储 GPU 处理所需的图形数据,如顶点数据、纹理、帧缓冲区、中间计算结果等。
作用: 显存提供了 GPU 快速访问数据的能力,避免了频繁访问系统内存所带来的延迟。显存的带宽和容量直接影响到 GPU 的性能表现,尤其是当处理高分辨率、高细节的游戏或专业图形应用时。
类型: 显存可以有不同的类型,如 GDDR5、GDDR6、HBM2 等,它们具有不同的带宽和延迟特性。显存的位宽和频率也会影响其带宽,进而影响 GPU 的数据吞吐量。
总结
GPU 是执行图形和计算任务的处理器,而 显存 是存储 GPU 执行任务所需数据的存储器。
GPU 的性能取决于其架构、核心数量、频率等因素;显存 的性能则由其类型、容量、带宽决定。
GPU 和 显存 需要协同工作,GPU 从显存中读取数据,处理后可能将结果写回显存,因此两者之间的通信效率对整体性能至关重要。
参考:https://tingsongyu.github.io/PyTorch-Tutorial-2nd/chapter-7/
参考:https://pytorch-cn.readthedocs.io/zh/latest/
参考:https://datawhalechina.github.io/thorough-pytorch/