https://github.com/QInzhengk/Math-Model-and-Machine-Learning
@[TOC](Linux jq 、vim以及Linux集群安装miniconda并配置虚拟环境)
一、jq
1
| zcat cent_g_20226/*.gz | head -n 10000 | jq .event | sort | uniq -c
|
jq 是一个轻量级的json处理命令。可以对json数据进行分片、过滤、映射和转换
jq . 对json数据进行格式化输出
常用选项
- -c 紧凑输出json数据
- -s 读取所有输入到一个数组
- -r 输出原始字符串,而不是一个JSON格式
- -S 排序对象
1、紧凑输出json数据
1
2
| jq -c . test.json
[{"lon":113.30765,"name":"广州市","code":"4401","lat":23.422825},{"lon":113.59446,"name":"韶关市","code":"4402","lat":24.80296}]
|
2、读取所有输出到一个数组(也就是所在json数据最外层套一个数组)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| echo '{"safd":"fsafd"}'
{"safd":"fsafd"}
echo '{"safd":"fsafd"}' | jq -r .
{
"safd": "fsafd"
}
echo '{"safd":"fsafd"}' | jq -s .
[
{
"safd": "fsafd"
}
]
|
3、输出原始字符串,而不是一个JSON格式
1
2
3
4
5
| echo '{"safd":"fsafd"}' | jq .[]
"fsafd"
echo '{"safd":"fsafd"}' | jq -r .[]
fsafd
|
4、排序对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| jq . test.json
[
{
"lon": 113.30765,
"name": "广州市",
"code": "4401",
"lat": 23.422825
},
{
"lon": 113.59446,
"name": "韶关市",
"code": "4402",
"lat": 24.80296
}
]
jq -S . test.json
[
{
"code": "4401",
"lat": 23.422825,
"lon": 113.30765,
"name": "广州市"
},
{
"code": "4402",
"lat": 24.80296,
"lon": 113.59446,
"name": "韶关市"
}
]
|
5、获取上面地理json数据里的name值
1
2
3
4
5
6
7
| jq '.[]|{name}' test.json
{
"name": "广州市"
}
{
"name": "韶关市"
}
|
6、获取第一个name值
1
2
3
4
| jq '.[0]|{name}' test.json
{
"name": "广州市"
}
|
7、只打印出第一个map的值:
1
2
3
4
5
| jq '.[0]|.[]' test.json
113.30765
"广州市"
"4401"
23.422825
|
8、打印出一个map的name值
1
2
| jq '.[0]|.name' test.json
"广州市"
|
9、打印出一个map的name值并用普通字符串显示
1
2
| jq -r '.[0]|.name' test.json
广州市
|
案例
测试json数据,如下:
1
2
3
4
5
6
7
8
9
10
11
12
| {
"name": "xueyuan",
"age": 21,
"birthday": "10th August",
"email": "im.hexueyuan@outlook.com",
"skills" : [
"C/C++",
"Python",
"Golang",
"Node.js"
]
}
|
使用python的json库把它处理为一个字符串,如下:
1
| {"skills": ["C/C++", "Python", "Golang", "Node.js"], "age": 21, "birthday": "10th August", "name": "xueyuan", "email": "im.hexueyuan@outlook.com"}
|
这个格式是我们在实际生产中经常看到的格式,比如我们使用curl请求一个接口,返回了一个json,比如我们在自己的项目中测试输出了一个json数据,这种格式往往可读性较差,我们需要进行处理后才能查看。
要转换成python处理前的那一种易读形式很简单,执行:
1
2
3
| cat test.json | jq '.'
|
jq把数据转换成易读格式,还添加了颜色高亮说明,其中key和value使用了不同的颜色。
1
2
3
4
5
6
7
8
9
10
11
12
| {
"skills": [
"C/C++",
"Python",
"Golang",
"Node.js"
],
"age": 21,
"birthday": "10th August",
"name": "xueyuan",
"email": "im.hexueyuan@outlook.com"
}
|
如果json数据很大,我们只想看其中某个字段数据,那么使用如下语法:
1
2
3
4
5
6
7
8
9
10
| cat test.json | jq .skills
[
"C/C++",
"Python",
"Golang",
"Node.js"
]
cat test.json | jq .name
"xueyuan"
|
当某个字段是一个列表,jq可以对其进行切片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| cat test.json | jq '.skills[0]'
"C/C++"
cat test.json | jq '.skills[0:3]'
[
"C/C++",
"Python",
"Golang"
]
cat test.json | jq '.skills[:3]'
[
"C/C++",
"Python",
"Golang"
]
cat test.json | jq '.skills[:]'
jq: error: syntax error, unexpected ']' (Unix shell quoting issues?) at <top-level>, line 1:
.skills[:]
jq: 1 compile error
cat test.json | jq '.skills[2:]'
[
"Golang",
"Node.js"
]
cat test.json | jq '.skills[]'
"C/C++"
"Python"
"Golang"
"Node.js"
|
注意和python列表切片方式进行区分。区别一下’.skills’和’.skills[]’两种,可以看到前者输出是一个列表,后者是非json格式的列表成员。
用法详解
jq从linux管道或者文件中获取文本输入,如果文本不满足json格式,那么jq会报错,可以用这个方法来检查一个文本是否满足json检查:
1
| jq '.' json_file > /dev/null
|
jq使用filter来处理json文本,并输出filter处理后的内容到标准输出,filter是用来过滤满足需求的字段的,比如最简单的filter ‘.’,这个表示无过滤策略,因此会输出全部json文本。
key filter
过滤满足key的字段名,输出这个key的值。
key-value filter
输出key和value,区别key filter,如下
1
2
3
4
5
6
7
| cat test.json | jq '{age}'
{
"age": 21
}
cat test.json | jq '.age'
21
|
因为key-value必须归属于某个对象,所以添加外层{}。
index filter
1
2
3
4
5
6
| '.<list-key>[index]'
'.<list-key>[index1, index2]'
'.<list-key>[s:e]'
'.<list-key>[:e]'
'.<list-key>[s:]'
'.<list-key>[]'
|
数组索引和切片,用来操作列表元素。
嵌套层级filter
用于嵌套的json数据filter。
多个filter
使用英文单字节逗号分隔filter,用于在一个filter中过滤多个字段。
filter管道
1
| 'filter1 | filter2 | filter3'
|
1
| jq '.contact | .phone | .home' people.json
|
由于大部分filter之后,输出仍然是一个json数据,所以可以将filter通过管道连接。
重新组织filter后输出的数据
有时候我们需要重新构造json的结构,比如去掉某一层嵌套,比如取某几个字段组成一个新的json,这时候我们需要重新改变json的结构,我们可以使用[]和{}来重新组织json。
1
2
|
jq '[filter1, filter2, filter3]' data.json
|
1
2
3
4
5
| cat test.json | jq '[.age,.name]'
[
21,
"xueyuan"
]
|
1
2
|
jq '{filter1, filter2, filter3}' data.json
|
1
2
3
4
5
6
7
8
9
10
| cat test.json | jq '{age,name,email,skills: .skills[2:]}'
{
"age": 21,
"name": "xueyuan",
"email": "im.hexueyuan@outlook.com",
"skills": [
"Golang",
"Node.js"
]
}
|
递归展开json结构
有时候我们需要在一个json里边查找某个字段,但是确不知道这个字段在哪个嵌套里边,如果嵌套很深那么很难找到,jq可以把嵌套展开打平之后再查找。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| cat test.json | jq '..'
{
"skills": [
"C/C++",
"Python",
"Golang",
"Node.js"
],
"age": 21,
"birthday": "10th August",
"name": "xueyuan",
"email": "im.hexueyuan@outlook.com"
}
[
"C/C++",
"Python",
"Golang",
"Node.js"
]
"C/C++"
"Python"
"Golang"
"Node.js"
21
"10th August"
"xueyuan"
"im.hexueyuan@outlook.com"
|
展开之后结合管道再次filter可以查找key。
length filter
计算元素长度,对于对象,length表示对象里的元素个数,对于string,length表示string字符数,对于列表,表示列表元素个数。
1
2
3
4
5
6
7
8
9
10
11
| cat test.json | jq '. | length'
5
cat test.json | jq '.age | length'
21
cat test.json | jq '.name | length'
7
cat test.json | jq '.skills | length'
4
|
keys filter
输出全部的key,列表形式
1
2
3
4
5
6
7
8
| cat test.json | jq '. | keys'
[
"age",
"birthday",
"email",
"name",
"skills"
]
|
检查某个key是否存在
如果输入是一个对象,那么对象的元素是以”key-value”形式存在的,使用
1
| jq 'has("key-name")' data.json
|
检查json对象是否含有某个key。
列表遍历
jq支持使用map()或者map_values()遍历列表,或者对象的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
| echo '{"a":1,"b":2,"c":3}' | jq 'map_values(1 + .)'
{
"a": 2,
"b": 3,
"c": 4
}
echo '[1,2,3]' | jq 'map(1 + .)'
[
2,
3,
4
]
|
删除某个key
1
| jq 'del(filter)' json.data
|
使用del()删除filter描述的key-value。
jq支持管道线 |,它如同linux命令中的管道线——把前面命令的输出当作是后面命令的输入。
二、vim
退出编辑模式:按esc键
命令行模式下相关命令
1.移动光标
- h: ← 左移
- l: → 右移
- j: ↓ 下移
- k: ↑ 上移
- gg: 光标移动文件开头
- G: 光标移动到文件末尾
- ^: 光标移动到行头
- 0: 光标移动到行首
- $: 光标移动到行尾
- 123G:跳转到第123行
2.删除字符
- x: 删除光标后一个字符,相当于 Del
- X: 删除光标前一个字符,相当于 Backspace
- dd: 删除光标所在行
- n dd 删除光标(含)后多少行
3.撤销操作
4.复制粘贴
- yy: 复制光标当前行,n yy 复制光标所在行(含)后多少行
- p: 在光标所在位置向下新开辟一行,粘贴
- P: 从光标所在行, 开始粘贴
5.可视模式
- v:按字移动
- 配合 h、j、k、l 使用
- 使用y复制选中内容
6.查找操作
- /hello -> 从光标所在位置向后查找 hello
- n: 下一个
- N:上一个
- ?hello -> 从光标所在位置向前查找 hello
- n: 上一个
- N:下一个
7.替换操作
8.文本行移动
9.Man Page
- 光标移动到函数上,Shift-k 光标移动到函数上
文本模式下相关命令
1. 进入输入模式
- i: 插入光标前一个字符
- I: 插入行首
- a: 插入光标后一个字符
- A: 插入行未
- o: 向下新开一行,插入行首
- O: 向上新开一行,插入行首
- s: 删除光标所在的字符
- S:删除当前行
末行模式下相关命令
1.行跳转
2.替换
(1) 替换一行
- : s/abc/123
- -> 将当前行中的第一个abc替换为123
- : s/abc/123/g
- ->将当前行中的abc全部替换为123
(2) 替换全部
- :%s/abc/123
- -> 将所有行中的第一个abc替换为123
- :%s/abc/123/g
- -> 将所有行中的abc全部替换为123
(3)替换指定行
- :10,30s/abc/123/g
- -> 将10-30行中的abc全部替换为123
3.执行shell命令
4.分屏操作
(1) 进入分屏模式
- 命令:sp 将屏幕分为两部分 –> 水平
- 命令:vsp 将屏幕分为两部分 –> 垂直
- 命令:sp(vsp) + 文件名 水平或垂直拆分窗口显示两个不同的文件
(2) 退出分屏模式
- 命令:wqall 保存并退出所有屏幕
- 命令:wq保存并退出光标所在的屏幕
- Ctrl+ww 切换两个屏幕
在一般模式当中,输入『 : / ?』3 个中的任何一个按钮,就可以将光标移动到最底下那一行。
在这个模式当中, 可以提供你『搜寻资料』的动作,而读取、存盘、大量取代字符、离开 vi 、显示行号等动作是在此模式中达成的!
- :w 保存
- :q 退出
- :! 强制执行
- :set nu 显示行号
- :set nonu 关闭行号
- ZZ(shift+zz) 没有修改文件直接退出,如果修改了文件保存退出
- :nohl 去除高亮显示
- :wq! 强制保存退出
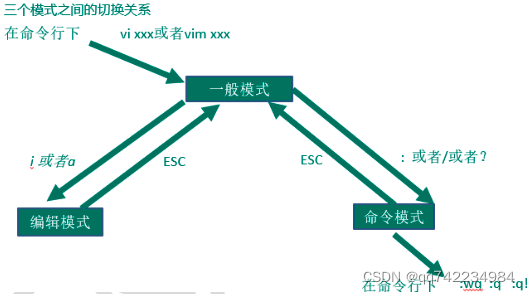
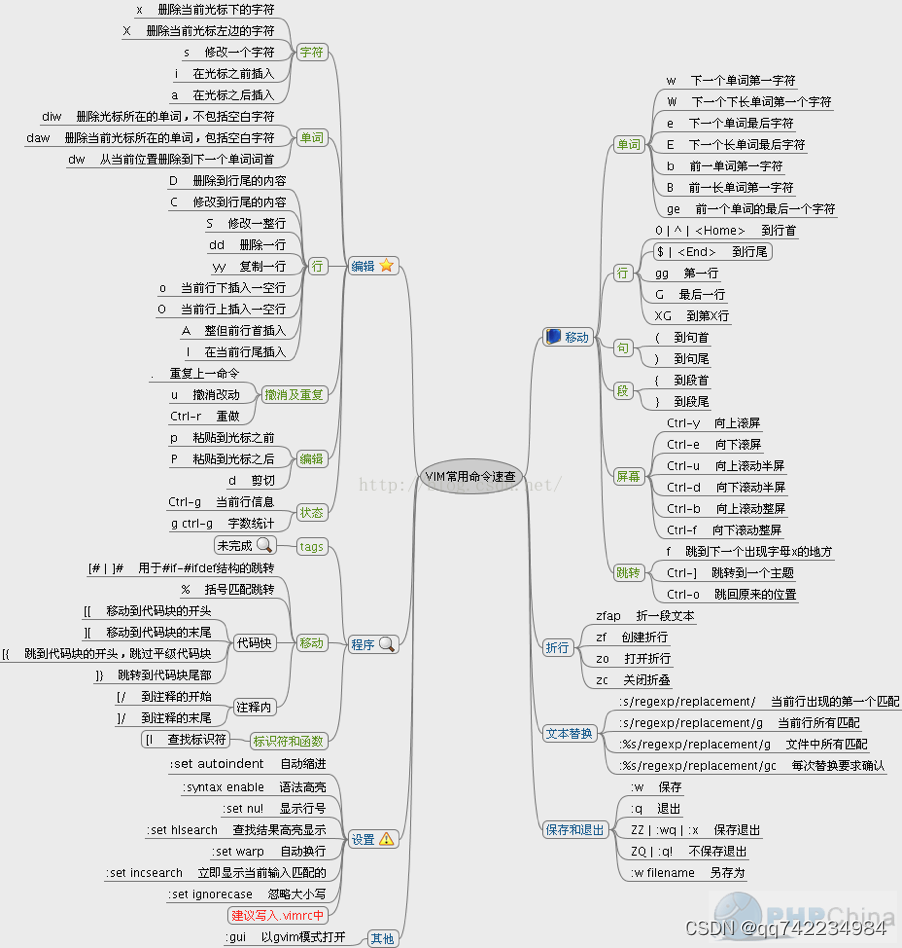
参考:https://blog.csdn.net/Cheat1173010256/article/details/118230562
三、LInux集群安装miniconda并配置虚拟环境
1.下载软件
1
| wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
|
2.安装
1
| sh Miniconda3-latest-Linux-x86_64.sh
|
3.激活
1
| source ./miniconda3/bin/activate
|
4.添加频道
1
2
| conda config --add channels bioconda
conda config --add channels conda-forge
|
5.添加镜像(清华源)
1
2
3
4
5
| conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --set show_channel_urls yes
|
6.查看
1
2
3
| conda config --get channels
or
cat ~/.condarc
|
7.环境管理
查看已安装的python环境
1
2
3
| conda info -e
conda env list
|
创建环境
1
2
3
4
5
6
7
8
9
10
11
|
conda create --name test python=3.7
conda create -n test2 python=3
conda create --prefix=/path/to/py37 python=3.7
|
启动或关闭环境
1
2
3
4
5
6
|
source activate(后接环境名,不加默认为base)
source activate test
source deactivate test
|
删除环境
1
2
| conda env remove -n test
conda remove -n test --all
|
重命名环境
即先克隆,再删除
1
2
| conda create -n python2 --clone py2
conda remove -n py2 --all
|
关闭环境